How can we get the benefits of IoC containers at a higher level - the services that we deploy into environments? Typical service tiers are implemented with a fronting load balancer that allocates servers to satisfy requests. Applications or services that need these services are give domain or IP information of the load balancers and the load balancers are given details of the servers running instances of the services that they need. Essentially each system with dependencies news an instance of its dependencies. Inverting this dependency requires a container but it leads to some interesting advantages.
Before digging into the detail lets define a few terms. Paul Hammant has an article differentiating components and services. For our purposes a service exposes an interface exposed over a medium like a network and the exchange of information involves converting the data to facilitate the exchange. Most of the services I write these days are RESTful in nature.
Most of the commercial projects I am involved in use multiple environments. An environment is typically discrete and has its own network (sub-net). This might be local to my development environment, a shared QA environment and perhaps a pre-production preview. The discrete nature of these environments is an important consideration when using these discovery mechanisms.
I am using the term IoC (Inversion of Control) liberally here.
Discovery
Applications build containers from specifications that are either defined in code or some external configuration. For services running within a networked environment the container is external to a component or application. Registration service components like Apache Zookeeper can be told about services. Zookeeper was originally an Hadoop sub-project but is now a top level Apache project. Zookeeper has a number of use-cases including discovery. Applications can ask about the services that are available and instances that provide those services. Operating in this way the directory service acts like a container.
But before the container can be used it needs to be found.
Discovery by convention
Jenkins and Hudson provides an interesting method of discovery through multi-casting.
UDP multi-cast/broadcast
Jenkins/Hudson listen on a UDP port (33848). Clients can broadcast a packet (e.g. targeting 255.255.255.255) or multi-cast packet (targeting 239.77.124.213). When a packet is received an XML response is sent to the UDP port of the sender. In this way Jenkins and Hudson servers running on the local network can be discovered.
The client and server share information about the protocol (XML format and ports) for discovery of the available instances. Once discovered further communication is directed to the running instance(s).
DNS multi-cast
DNS muli-cast achieves the same result based on the shared knowledge that Jenkins/Hudson advertise themselves as “_hudson._tcp.local”. The version, url and port information are advertises in the DNS record of the server.
More details of these approaches can be found here.
Using the container
For our situation we need to discover a registration. Lets assume Zookeeper is the registrar and that is does not advertise itself on the local network (I could not find such a feature in the docs). It would be relatively straightforward to add a responder that worked in a similar way to Jenkins/Hudson to the running Zookeeper or Zookeeper cluster that would allow clients to discover the registrar and then make use of it.
Service registration
Each time a new service instance starts up on the network it first identifies the local registrar (e.g. zookeeper). Once identified it queries for the services it needs (perhaps looping until they are all available). Once received the service can continue initializing; connecting to the services it needs to perform its functions (e.g. database and service endpoints). When it has complete initialising itself it then registers itself to start receiving traffic.
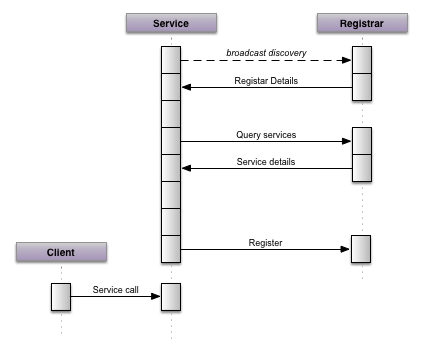
There are some interesting benefits to this approach. Services typically take time before they are ready to reliably service requests. Perhaps caches need to be primed or configuration received and processed. By delaying service registration until after the service is ready we avoid overwhelming the service instance by sending traffic to it too early.
Scaling in this environment is also simpler. More service instances can be started without additional configuration in the environment. Each new instance discovers the environment dynamically and adjusts its settings accordingly.
Monitoring systems can ‘hook’ into the registry to discover the available services and how each instance can be monitored.
Zookeeper polls services to make sure that they are still available. If a service fails to respond or is causing errors it is removed from the registry.
Taking this a step further monitoring can fire up new instances dynamically to compensate for individual failures or increasing demand.
Auto-scaling and resilience
Netflix Chaos Monkey actively seeks out auto scaling groups and terminates instances. This approach encourages the system to be self-healing. New instances come into being to compensate for the loss. By shifting to discovery and a service container we could encourage services to self-expire. A service starts and decided how long it should live based on some configuration of fixed value (perhaps randomly within a lifetime range to avoid every service expiring at the same time. When a service instance reaches the end of its lifetime is initiates the creation of its replacement. Some time later the replacement advertises that it is able to take on the parents role allowing the parent to expire.
A true Phoenix server?