
Event Sourcing
Event Sourcing is a fascinating design pattern. In an Event Sourced applications/systems instead of storing the current state we derived the current state from a list of events. Many articles and presentations talk about event sourcing, CQRS and event driven as a single topic but it is important to recognise what each pattern contributes to the overall design. Event sourcing can be used within a single application to great effect. In one of his video presentations Greg Young describes a partially connected application where event sourcing made synchronising state much easier than trying to reconsile two stores of current state.
Version control systems are good examples of event sourcing - particularly Git. Each commit is stored as an event representing a change of state - files/lines to be added/removed. Git is a distributed version control system. Changes in a git repository on one machine can be merged relatively easily into another repository (typically the origin) because each commit is essentially an event describing a change of state.
Event driven, CQRS and Evnet Sourcing are complementary patterns so it makes sense to consider them both as a set and individually. This article is the latter - a focus on event sourcing.
Requests are turned into events and stored in order in an event store.
Figure 1. Handling a request
The request handler validates the registration request checking that the name/email are valid, not already valid and any other checks that are required. Once these check pass the event is generated and put in the event store. Notice that there semantics are different between the request and the event. A request is just that a request to change the state of the system, sometimes requests are called commands - again a subtle distinction but often this reflects the semantics of the business better. The service can decide not to honor the request. The event on the other hand is a statement of fact - we have a new customer. The event is temporal. Events reference a moment in time. The customer could close their account but until that happens there is a customer record generated by processing the events.

Figure 2. Handling a Query
You’ll notice that I introduced <id> as a unique key. This id is typically generated as part of the request handling to find the event list in the event store and as a key for clients to reference later.
The key processing difference is step [4] where the event is processed into a customer record.
To see how event sourcing works we need a few more events.

Figure 3. Updates
The number of events goes up in proportion to the command requests received. In some situations multiple events might be generated from a single command although most implementations I have seen typically map a command to an event. Over time long lived entities can build up sizeable event stores. A stock price for example might change hundreds of times in a single day. As the number of events increases it becomes impractical to rebuild by processing all events and caching as a 'snapshot' is often used minimizing the number of events that need to be processed.
It is interesting to think of event processing in terms of functional programming. The entity state is the reduction of all events by applying a processing function recursively to the entity and the event. Jumping straight in here is a snippet of Clojure code. The full project can be found here: https://github.com/grahambrooks/functional-event-store
The event store is a simple list of events. Processing them means applying the event to an entity. For the initial creation event an empty entity template is used. In clojure the entity can be represented as a simple map
{:entity-type customer
:name "Graham"
:email "[email protected]"}The same it true for events. A map structure can be used to represent the event.
{:event-type new-customer
:name "Graham"
:email "[email protected]"}Initially though we don’t have a valid customer record. Instead we can start with an empty template:
{:entity-type customer
:name nil
:email nil}Applying the new-customer event to this emtpy customer record generates a more valid looking customer record.
{:entity-type customer
:name "Graham"
:email "[email protected]"}To create a customer entity’s current state we apply a processing function to the entity and the events one at a time until the event store is exhausted.
Processing events
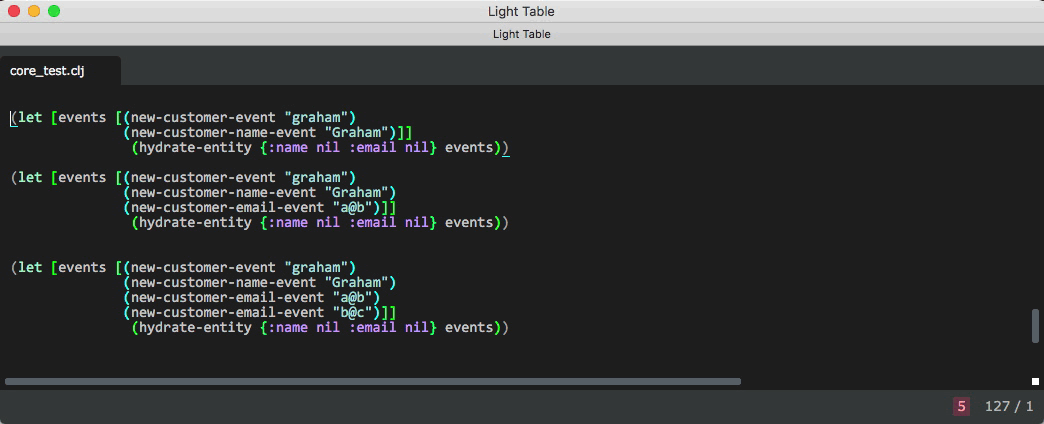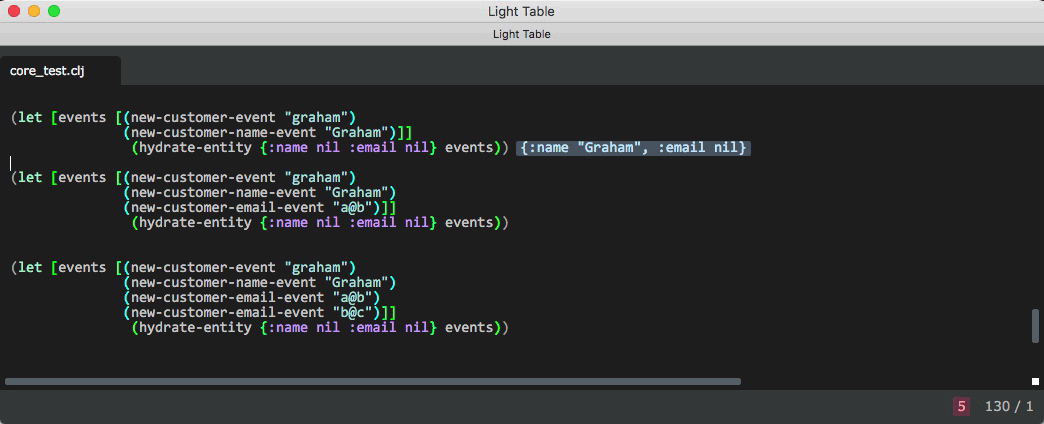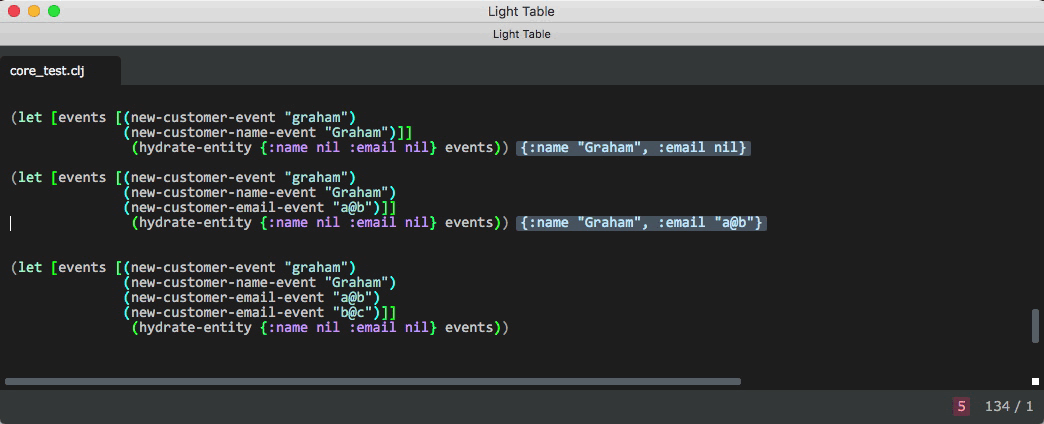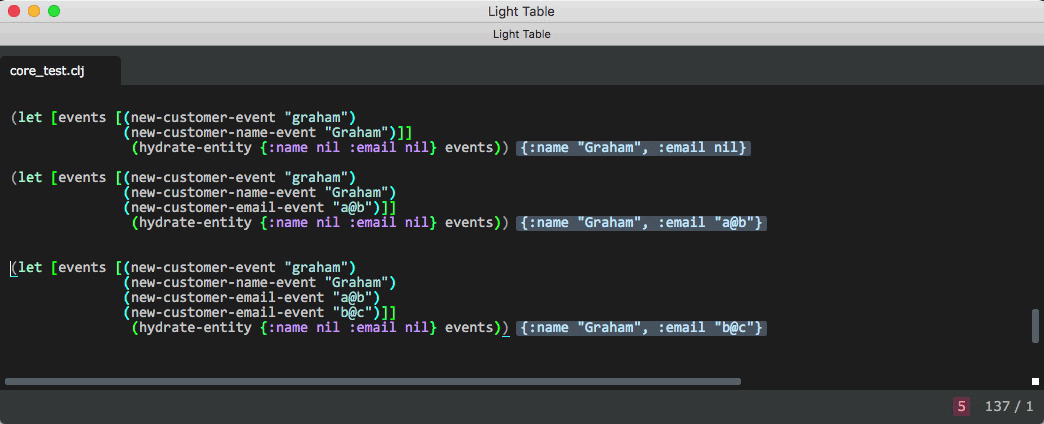
hydration function
(defn hydrate-entity
[entity events]
(if (empty? events) entity (hydrate-entity (handle-event entity (first events) handler-map) (rest events))))Processing an event
(defn handle-event
[entity event handlers]
(let [event-type (:event-type event)
handler (event-type handlers)]
(handler entity event)))Because events represent a subset of application state at a point it time they are typically stored immutably. This has a number of advantages. If events are forwarded to other systems they can store them safely if needed. If we find a bug in the way we are processing events we can fix the bug so that processing the events produces the right state. Diagnosing problems is much easier when you have a log (event) for every change in chronologial order. You know what changed and when.
Events and entities don’t have to have the same attributes. We might not need all the state to process a command or present a view of the entity. As an optimization we only need to build an entity that meets our processing needs. If at a later time we need another piece of data from an event we can just add it to the routine building the entity from the events. Keeping entities simple (fewer attributes) makes them faster to build and understand. An entity only needs to satisfy its validation requirements for commands and its query responsibiltes. If you combine Event Sourcing with CQRS then events can be used to generate view or query projections - essentially a cached current state view. Event Sourcing, CQRS and event driven systems are often grouped together. There are advantages to this approach. Each pattern/technique builds upon the other. But it is also important to understand what benefits and problems each contributes to a solution.
Event Sourcing and Audit
Many systems need to be audited. Medical and financial systems are the most well known. Event Sourced systems are particularly attractive because the audit trail is key to a functioning system - the event store is the audit trail. Traditional systems that maintain a current state view within the system usually generate an independent audit trail of changes. This could be an application or database log. Because these are orthogonal to functionality they need additional testing to show that changes generate audit logs and that the logs contain useful auditing data. Event Sourced systems inherently satisfy these requirements and functional tests act as tests that the audit trail is right.
Event Sourcing is currently more complex than implementing a 'current state' system but in regulated environments with strong auditing requirements Event Sourcing can be a good choice.
When things go wrong
Things always go wrong. API changes in integration points.
Many errors can be handled by using existing APIs - correcting changes of address, name orders etc. Some problems will need custom solutions - the problems we did nor foresee.
Another complex area for event based systems are side-effects. Any action taken in response to an event become more difficult when problems happen.
Data errors are often handled by just changing the data. When we maintain state in say a relational database if something goes wrong and we have errors changes can be quickly made by running an SQL script to correct the problem. For Event Sourced systems we need to introduce an event that represents a corrective action.
Lets say I change my name from graham to Graham. At the time of the change there is a bug in the request/command handler that adds a '!' to the end of every name so my name is recorded as Graham!. While flattering it’s not the expected result.
We could simply query for all records that have been affected and send the appropriate requests to correct the error. The change would propagate through the system in the same way as previous events have. For this example this action may be appropriate. When the error has affected a lot of data it may take some time but the error would be corrected. Other systems may be listening to these events. When we correct the data these systems will receive another address-change event, another email or letter may be sent. For a simple name correction this might be fine but for other errors we probably want some level of control over what happens downstream.
Other areas may not be correctable by making an existing request. Events may have been issued incorrectly because of previous errors that have compromised the list of events. These past errors may be technically straightforward - introduce a new event that corrects the state but the impact to the overall system as they respond to events is far more complex.
Lets consider a banking system using Event Sourcing. Some time in the past a transaction request introduced an event that adjusts the available balance. Due to a rounding error or some other arithmetic problem the amount was wrong - e.g. $101 instead of $100. Lets also assume that we have not seen this problem before. The good news is that we have the event history and know exactly which events were issued in error. It takes some analysis but working out what the corrections would be is a lot easier with the history in the event store. The changes may need a new event type to be introduced.
Adding new event types for each defect is problematic. Each new event we create becomes an immutable part of history which means that any system receiving events needs to handle this event forever.
This is a conundrum. We want the event store to contain state changes as events. A single corrective action should be represented as a single event but we could choose to represent the change as a number of events.
- Options
-
-
Use a combination of events that when applied correct the error
-
Use a 'whole state event' or 'snapshot' in the event store to correct the state.
-
Use a 'meta' event that 'pragmatically' corrects the problem
-
-
Multiple events
Given that the entire entity record is generated from events it should be possible to generate an event sequence that corrects the record state. The events need to be identified that they are part of a corrective action. Downstream systems that listen to the event stream will have problems understanding the event sequence without additional data on how the events should be applied.
Snapshot events
A snapshot event essentially contains a collapsed view of the multiple events option or the entity state to be applied. Additional meta-data within the event helps recipients process it correctly.
Meta events
Multiple and snapshot events create noise and bloat in the event store. Other systems receiving the events need additional data or programming to handle the events because the context of the error will not be known to them.
The meta data event includes programmable logic specific to each recipient. The entity in the event store and any downstream listeners. This does mean that each system that handles events needs to support these events.
So how does this work
For Meta events to work we need to view the overall system. The corrective action needs to applied to all affected systems and services. The change to each is specific to the system.
- Events need to be targeted
-
A meta event needs to contain data so the receiving system knows if it should use the event. This could be metadata in the event or some predicate data or method in the event.
:systems-affected [:sales :orders]If targeted the target system needs the ability to interpret the event.
Event processing
It is likely that each compensating event is going to be unique. Processing the event needs to be flexible both in what it needs to do and the technologies used to process it.
If the system is closed (owned by a development team) and based on the smae runtime then a library or framework can be developed to process these events in each system (shared code). This means that we could choose to embed code inside the events. Dynamic languages and runtimes are particularly attractive options here.
Where diverse technologies are in play an external DSL might be more appropriate. The DSL interpreter is implemented in the service language. Each system or component is required to handle these events.
When they do (at the most inconvenient time) development teams need to come up with solutions.
As mentioned earlier Event Sourcing is very useful in diganosing problems
Clojure and Functional Event Sourcing
|
This work is (at best) a PoC to explore how a functional language might work in an event sourced application. I am also a novice Clojure programmer so improvement suggestions welcome. |
The full source can be found on github https://github.com/grahambrooks/functional-event-store
Lets start with events. In Object Oriented languages like Java we would probably define a class to represent each event type and use marshaling to load and save those object to the object store. In Clojure we cam define those structures as records using defrecord using a simple hashmap makes it easy to map between the map and say JSON or YAML for storage or transmission..
Adding a function to build the event is a convenience.
Events
(defn new-customer-event
([name] {:event-type :new-customer
:name name
:email nil})
([name email]
{:event-type :new-customer
:name name
:email email}))
(facts "about new customer events"
(fact "customers can have just a name"
(new-customer-event "fred") => {:event-type :new-customer
:name "fred"
:email nil})
(fact "customers can start with name and email"
(new-customer-event "fred" "a@b") => {:event-type :new-customer
:name "fred"
:email "a@b"}))The entity or aggregate can be defined in the same way - a hashmap. Because we are using functions to manipulate the entity based on events all of the work in done in processing.
Sparse Aggregate
(let [aggregate (defaggregate {:name nil})]
(handle-new-customer-event aggregate (new-customer-event "Graham Brooks" "[email protected]")) => {:name "Graham Brooks"}))The sparse aggregate example above shows how we could create a customer record with just the customer name and ignore the email address. If this changes then changing the definition of the aggregate changes how the event is applied.
Full Aggregate
(fact "event changes all event fields"
(let [aggregate (defaggregate {:name nil :email nil})]
(handle-new-customer-event aggregate (new-customer-event "Graham Brooks" "[email protected]")) => {:name "Graham Brooks" :email "[email protected]"}))Updating the aggregate based on events is where all the action is. Here again because we are applying changes to a hashmap of values applying event data can be generalized quite nicely.
Events
(defn default-handler
[entity event]
(merge entity (select-keys event (keys entity))))
(defn handle-new-customer-event
[customer event]
(default-handler customer event))Handling new customer events delegates to the default handler which queries for the map keys in the aggregate, selects those values from the event and merges them with the current state of the aggregate or entity.
Processing all the events in an event store involves applying the appropriate handler for an event.
Events
(def handler-map
{:new-customer handle-new-customer-event
:new-customer-email handle-new-customer-email
:new-customer-name handle-new-customer-name})Being able to store functions in the map makes defining how events are processed by type nice and simple.
Hydrating entities
(defn hydrate-entity
[entity events]
(if (empty? events) entity (hydrate-entity (handle-event entity (first events) handler-map) (rest events))))
(defn handle-new-customer-event
[customer event]
(default-handler customer event))The hydrate-entity method pulls events off the list one at a time,
applying the event data into the entity. When the list is empty the
developed entity state is returned.
Tying it all together is the handle-event method that applies the
appropriate handler function for the event.
(defn handle-event
[entity event handlers]
(let [event-type (:event-type event)
handler (event-type handlers)]
(handler entity event)))You have probably noticed that this code is overly simplified for real world applications where aggregates/entities are more complex. You might also notice that I am fairly new to clojure. I would really appreciate feedback or pull requests on how this code could improve.
Wrapping up
Event Sourcing as a pattern is extremely powerful.
-
It improves our ability to diagnose root causes of errors by recording a full history of changes
-
It inherently supports audit requirements with a self proof of correctness
-
It records corrections explicitly in the event store
When applied to distributed systems
-
The programming model is more complex and harder to grok
-
Side effects to event processing need to be carefully managed - particularly when fixing data problems.
-
Events are retained for a long time and histories can then become difficult to manage.
- References